서론
인공지능과 IoT 시대의 도래로 우리는 소형부터 대형까지 다양한 기기들 속에서 살고 있다. 이 모든 기기들은 인터넷과 연결되어 네트워크 상으로 정보를 주고받는다. 이 말은 즉, 전 세계 아니, 전 우주(전파들)에 모든 데이터와 정보들이 돌아다니고 있다는 뜻이다. 결국, “이미 엎질러진 물은 주워 담을 수 없다” 라는 여느 속담처럼 우리가 메신저로 누군가에게 보낸 사진, 블로그에 올린 텍스트 등의 정보들은 아주 짧은 순간이라도 내가 가진 기기를 떠나 세계를 항해하게 된다. 결국, 현재 인간들이 제정한 보안 기법과 법을 통해 내 정보가 어느 정도 보호가 되긴 하지만, 사실 전자기기를 쓰는 모든 순간 순간 나의 데이터는 보안의 위협 속에 살아가고 있다고 볼 수 있다.
이런 상황에서, AI (인공지능) 기술은 정확도와 실용성의 여부를 떠나 우리 일상 속으로 파고들어 오고 있다. 핸드폰에 담긴 음성 인식 서비스가 나의 질문에 대답해주고 있고, 친구들과 찍은 사진 속에서 친구들의 얼굴을 인식하여 사진을 자동으로 분류해준다. 심지어 인공지능이 만든 가상 인간이 TV 광고 속에 나타나기도 한다. 이런 인공지능 기술은 그냥 마법처럼 나타나는 기술이 아니다. 보통 기반 데이터가 있어야 고도의 훈련된 인공지능이 나타나는 것이다. 여러 사진 속에서 사람의 얼굴을 감지하게 하기 위해서 최소 10,000 여장의 샘플 얼굴 데이터를 사용하는 것처럼 말이다. 또한, 인공지능 훈련을 위해서는 이런 대량의 데이터들을 관리 및 전처리, 또 이를 이용한 복잡한 수학 계산 등이 필요하다. 이는 우리 스마트폰(아이폰, 갤럭시 등)이 할 수 있는 영역이 아니다. 마치 동네 포장마차에서 군대 한 대대를 위한 단체 주문을 처리해야 하는 순간을 생각하면 된다. 부대 한 대대에 10,000 명의 병사들이 있는데, 평소 한번에 최대 10여명의 손님을 받았던 포장 마차에서 해당 대대에서 단체 주문이 들어온다면, 주문을 모두 처리할 수 없을 뿐더러 이를 위해 준비 시간이 일주일은 필요할 것이다. 그래서 우리는 이런 경우에 대기업의 도움을 받는다. 대기업 케이터링 서비스 혹은 급식 제공 업체를 부르던가 말이다. 이처럼 AI 업계에서도 대량의 데이터와 복잡한 훈련 과정은 대기업에서 제공하는 고급 자원들을 사용해야 하므로 그 쪽에 훈련 과정을 위임한다. 이런 서비스를 제공하는 기업을 클라우드 기업이라고 한다.
곧, 인공지능 모델 훈련은 내 핸드폰이 아닌 다른 곳에서 진행할 수 있다는 것이다. 그 훈련을 위해 필요한 나의 데이터들이 그 다른 곳으로 전달 되어야 한다는 것이다. 그 다른 곳으로 전달 하기 위해서 내 데이터들을 네트워크 상으로 뿌려야 한다는 것이다. 결국에, 내 데이터들이 보안의 위협에 노출되는 상황이 더욱 많이 생긴다는 것이다. 이는, AI 발달로 도래하는 새로운 보안 이슈 중에 하나라고 볼 수 있다. 이처럼 기존의 보안 위협과 다르게 인공지능 기술의 발달과 함께 새로이 나타나게 되는 보안 이슈들이 있다. 오늘 글에서는 해당 위협이 어떤 것이 있는지 간략하게 살펴보고자 한다.
본론
[1] 에서는 ai security threats (ai 보안 위협) 에 대해서 다음 그림과 같이 정의하였다.
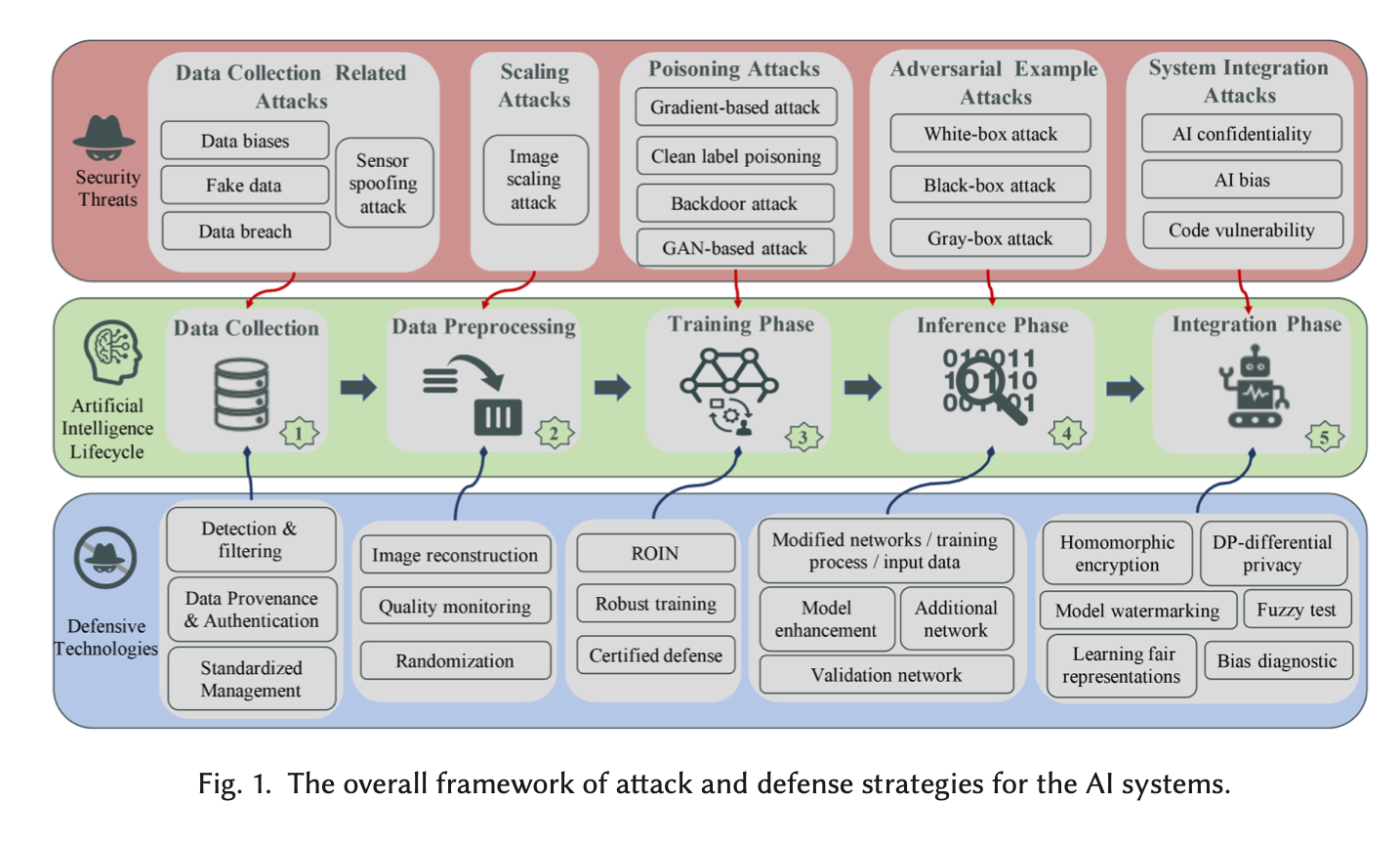
본 포스팅은 이 정의에 대해서 ai system 에 대한 각 과정별로 security threats 에 대해 서술할 것이다.
1. data collection phase (데이터 수집 과정)
데이터 수집 관련 보안 이슈에 대해서 말할 수 있다. 우리는 카메라로 영상, 사진 데이터를 수집하기도 하고 온도 센서로 시간에 따른 온도 데이터를 수집하기도 하는 등 다양한 데이터를 수집한다. (이는 단지 AI 영역에만 국한되지 않고 다양한 상황에서 나타나는 과정들이다.) [1]의 저자는 데이터 수집 영역에서 보안 위협은 하드웨어 기반 수집(Hardware based collection) 과 소프트웨어 기반 수집(Software based collection) 으로 나누어 설명했다.
H/W 기반 수집에서는 온도 센서와 같은 수집 기기로 부터 측정된 실질적 데이터들을 디지털 수치로 변환하여 수집하는 것을 대표적인 예로 들 수 있다. 이런 센서 수집 데이터들은 Sensor Spoofing Attack (센서 스푸핑 공격)의 위협을 받을 수 있다. 스푸핑 공격은 기존 보안 영역에서 합법적인 사용자가 아닌데 합법적인 사용자인 척 위조 데이터를 보내는 것이다. 그래서 센서 스푸핑 공격은 희생된 센서에 악의적인 데이터를 마치 진짜 데이터인 척 주입하는 것을 의미한다. 결국, 의미가 변질된 악의적인 데이터가 진짜 데이터 마냥 계속 수집 되는 것이다. [2]
S/W 기반 수집은 인터넷 네트워크 로그 같은 소프트웨어 적으로 생성되는 데이터를 수집하는 것을 의미한다. 이 과정에서 해당 데이터를 수집할 수 있는 소프트웨어 프로그램, 운영체제, 디바이스 드라이버 등이 함께 사용된다. 이런 상황에서 보안 위협은 데이터 편향(data bias), 가짜 데이터 (fake data), 데이터 위반 (data breach) 를 예로 들 수 있다. 그 중에서 데이터 편향은 AI 훈련에 쓰이는 데이터들이 특정한 집단, 특징들에 집중되어 있는 경우에 나타난다. 이는 인종,성 차별과 같은 정치적 이슈를 불러오기도 한다. 최근 국내를 떠들썩하게 했던 ‘이루다’ 논란을 예로 들 수 있겠다. [3]
2. data preprocessing phase (scaling attack) (데이터 전처리 과정)
이미지 관련 인공지능 모델은 보통 해당 모델의 인풋(input)으로 들어가는 이미지의 크기가 정해져 있다. 32x32 나 224x224 크기 정도의 이미지들이 통상적인 인풋 크기로 많이 쓰인다. 그렇기 때문에 일상에서 생겨나는 이미지는 이 모델의 인풋 사이즈에 맞춰질 필요가 있다. 이를 위해 data pre-processing (데이터 전처리) 과정에서는 이미지 scaling (스케일링) 작업을 진행한다. 이 과정에서도 원래의 데이터가 위협 받을 수 있다. 보통의 이미지 스케일링 알고리즘을 악용해서 위장 이미지를 만들어서 원래의 정답과 다른 정답이 나오도록 하는 것이다. 예로, 늑대의 사진을 받아서 특수한 스케일링 작업을 진행해, 시각적으로 양과 비슷한 이미지를 만들고 이를 인풋으로 넣어 동물 분류 모델의 결과(output)가 ‘양’이 나오게 한다. 이 인풋을 다시 원래의 사이즈로 re-scaling을 하면 원래의 늑대 사진이 그대로 나온다. 이러한 스케일링 공격은 공격 대상 모델의 정보를 알지 못해도 공격 시도가 가능하다. 이를 black-box 공격이라고 한다. 이것이 가능한 이유는 모델에 사용되는 이미지 사이즈, 리스케일링(rescaling) 알고리즘들이 매우 한정되어 있기 때문이다. 따라서, 모델의 직접적인 정보를 알지 못해도 한정적인 기법들을 유추함으로써 스케일링 공격을 시도할 수 있다.

3. model training phase (data poisoning attack) (모델 훈련 과정)
모델 훈련(training) 과정에서 데이터의 질(quality)은 매우 직접적으로 모델의 성능에 영향을 미친다. 이 관점에서 공격자는 훈련 데이터를 오염시켜 모델을 자기 입맛대로 조작할 수가 있다. 이를 poisoning attack 이라고 한다. 이 공격은 크게 두 가지로 나눌 수 있다. 첫 번째는, availability attacks (가용성 공격) 이고, 두 번째는 integrity attacks (무결성 공격) 이다.
availability attacks 은 모델의 loss를 최대화 하고 그러므로 모델의 전체 성능을 저하 시키는 것을 목적으로 한다. 이는 DoS(denial-of-service attack) 으로 불리기도 한다. 즉 sns chatbot 모델에서 의미 없는 문맥의 문장 데이터를 대량 생산시켜 모델의 성능을 저하시킬 수 있다. 오버워치, 롤 같은 팀 게임에서 게임과 상관없는 행동을 해서 게임을 지게 만드는 (매우 얄밉고 재수없는) 어그로꾼 혹은 트롤 이라고 생각해도 되겠다.
Integrity attacks 은 목표한 특정 부분에 대한 성능이 저하되도록 데이터를 오염 시키는 것을 말한다. 대표적인 예로 backdoor attack (백도어 공격)이 있다. 이는 특정한 유도 요인(trigger)들이 포함된 데이터만 이상하게 결과를 내는 것이다. 그래서 전체적으로 봤을 때는 모델이 정상적으로 동작하는 것처럼 보이지만 특정 데이터에 대해서는 비정상적인 동작을 하게 된다. 이는 겉으로 보기에 티가 나지 않기 때문에 백도어 공격이라고 부른다.
4. inference phase (adversarial example attack) (모델 추론 과정)
adversarial example(적대적 샘플) 은 AI 를 공부하는 사람이라면 익히 들어봤을 법 하다. 현재 가장 연구가 활발히 되고 있는 AI 관련 보안 이슈이기 때문이다. adversarial example 은 이미 완성된 모델을 이용해 결과를 추론하는 과정에서 나타난다. 즉, 깨끗한 인풋(input) 데이터에 사람이 인식 불가능한 노이즈(noise)를 추가 시켜서 전혀 틀린 결과(output)가 나오도록 하는 것이다. 해당 공격 관련한 기법으로 유명한 Goodfellow 아저씨가 참여하신 FGSM adversarial example 기법이 있다. [4] 이는 이미지 분야에서 대표적인 adversarial example 생성 알고리즘이다. 이런 이미지 분야 말고도 자연어 처리, 음성 인식, 악성 코드 인식 (malware detection) 과 같은 분야에서도 많은 연구가 진행 중이다.

5. AI system integration phase (AI 서비스 통합 과정)
AI 그 자체 뿐 아니라, AI 서비스를 위한 과정에서도 여러 보안 이슈들이 나타난다. 실생활에서 인공지능 기술이 서비스 되기 위해서는 AI 모델 그 자체만이 아니라 클라우드 서비스, 인공지능 모델 성능 개선, 모델 서비스 배포, 등 다양한 시스템적 기법이 뒷받침 되어줘야 한다. 이 과정에서, AI 서비스를 위해서 개인 데이터를 네트워크 상으로 보내야 할 수도 있고, 또 서비스 되고 있는 모델의 정보가 네트워크를 통해 유출이 될 수도 있다.
이 과정에서 나타날 수 있는 보안 이슈들은 다음과 같다. 첫번째로 model inversion 과 model extraction 이다. model inversion 은 이미 완성된 모델에서 모델 훈련에 쓰인 개인적 데이터를 유추하는 것이다. model extraction 은 이제 완성된 모델에 input, output 을 많은 쿼리를 통해 얻어서 이와 엇비슷한 모델을 만들어 버리고 그에 대한 parameter 값들을 유추하는 것이다. 따라서 이에 대한 해결법으로 모델에 저작권을 입력하는 model watermarking 이라던지, 모델을 아예 암호화해서 네트워크에 올리는 동형암호(homomorphic encryption) 등의 기법이 제시되고 있다.
또한, 개인 데이터 보호를 위해 Federated Learning 기법도 구글 리서치팀을 통해 제시되었다. [5] 이는 개인 데이터를 네트워크에 올리지 말고 그 개인 데이터가 저장된 기기 혹은 그 주변 기기를 통해 모델을 새롭게 훈련 시키고, 이 훈련된 모델 자체를 중앙 서버로 전달해서 중앙 서버에서 최종 향상된 모델을 생성하자는 아이디어다. 즉, 개인 데이터가 직접적으로 네트워크에 올려질 필요가 없으니 개인 데이터 보안을 강화할 수 있다는 것이다.

그러나, 여러 논문을 통해 훈련된 모델 자체도 model inversion 과 같은 방법으로 해킹을 당할 수 있다는 것이 증명되고 있다. [6] 이에 대해서 그러면 로컬에서 보내는 훈련 모델 자체도 동형 암호를 통해 암호화 하여 보내자는 아이디어도 제시되고 있지만, 동형 암호 과정이 매우 오래 걸리고, 데이터 사이즈가 방대해지기 때문에 실생활에 적용하기에 많은 비용(overhead)이 든다. 따라서 이런 비용을 최적화 하기 위한 연구도 활발히 진행되고 있는 중이다.
참고
[1] Artificial Intelligence Security Threats and Countermeasures (ACM Computing Surveys, Nov 2021)
[2] This ain’t your dose: Sensor Spoofing Attack on Medical Infusion Pump (USENIX, Aug 2016)
[3] http://www.knnews.co.kr/news/articleView.php?idxno=1342335
[4] Explaining and harnessing adversarial examples.(arXiv, Mar 2015)
[5] Communication efficient learning of deep networks from decentralized data. (arXiv, Feb 2017)
[6] Inverting Gradients - How easy is it to break privacy in federated learning? (NeurIPS, Sep 2020)



