서론
AI/ML 의 Natural Language Processing (NLP) 분야에서 각광받고 있는 Transformer 구조를 Language 가 아닌 Vision 영역에 적용한 Vision Transformer(ViT) 라는 구조가 2021 년도 ICLR 라는 학회에 발표[1] 되었다. 그 이후로도 현재 ViT 베이스의 모델 구조가 비전 분야에서 많이 연구 되고 있다.
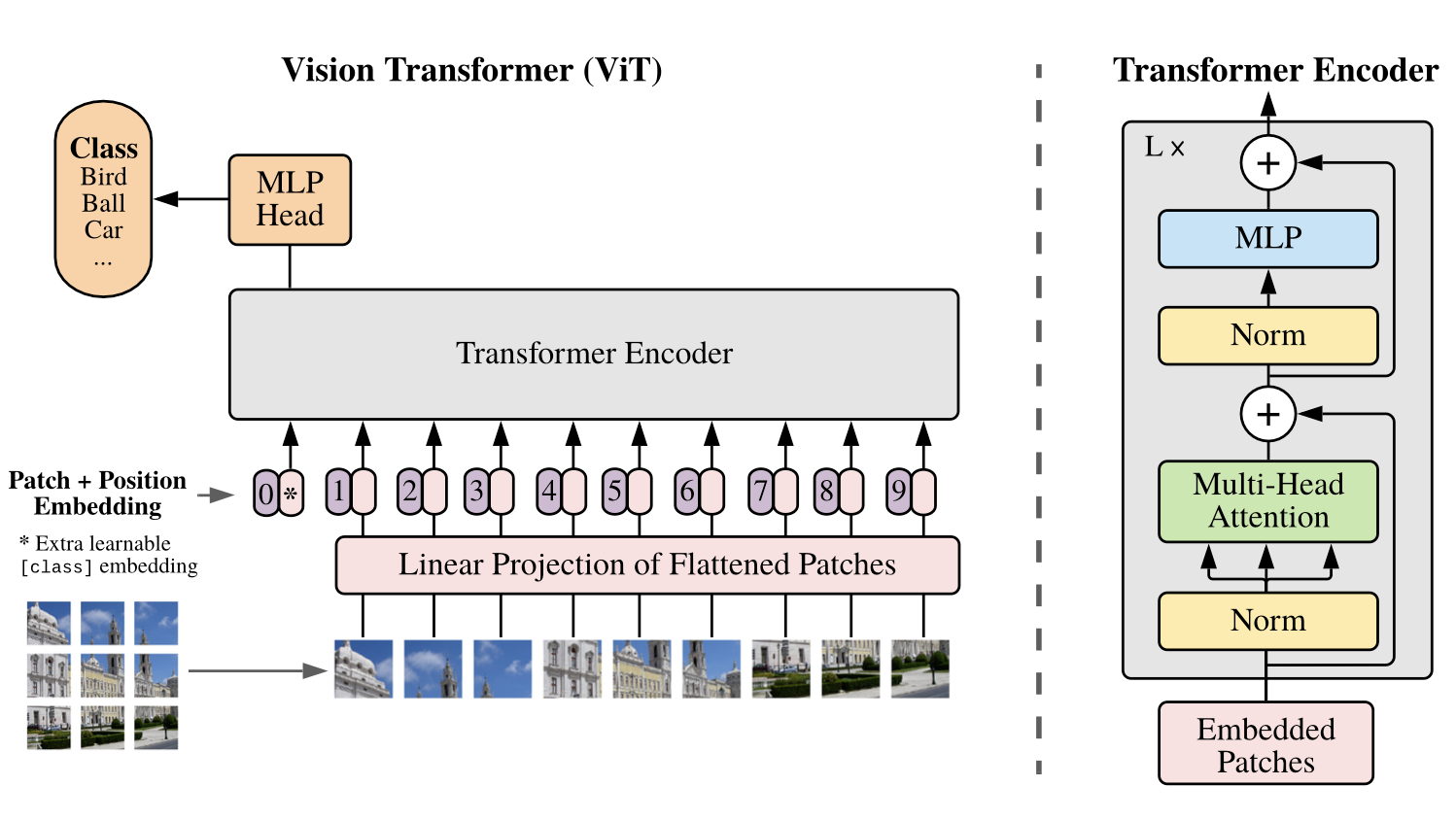
[1] 에서 나온 가장 기본적인 Vision Transformer 의 구조는 위 그림과 같다.
본 글은, Vision Transformer(ViT) 의 이론적인 이야기보다는 ViT 의 구조를 [2]의 코드와 함께 파헤쳐보고자 한다.
아래 부터는 쉬운 이해를 위해 직접 그린 그림들이 있다. 아래 그림들에 행렬(matrix) 들에 적혀진 숫자는 임의의 숫자이다.
ViT 에 들어가는 이미지는 32x32x3 의 1장이고 Patch size 는 16 이다.
Image Patch
여기는 32x32x3 의 이미지를 여러개의 patch 로 나누어서 본격적으로 embedding layer 에 들어갈 vector 를 만들어내는 과정이다.
아래 그림의 예시를 보면, 32x32 의 이미지를 16x16 의 patch 로 나누면 2x2=4개의 patch 가 나온다. 3인 channel 까지 따지면 각 patch 는 16x16x3 으로 이루어져 있다. 이를 flatten(일자로) 하게 1x768 크기의 vector 로 변형해서 최종적으로 4x768 의 matrix 가 생성된다.
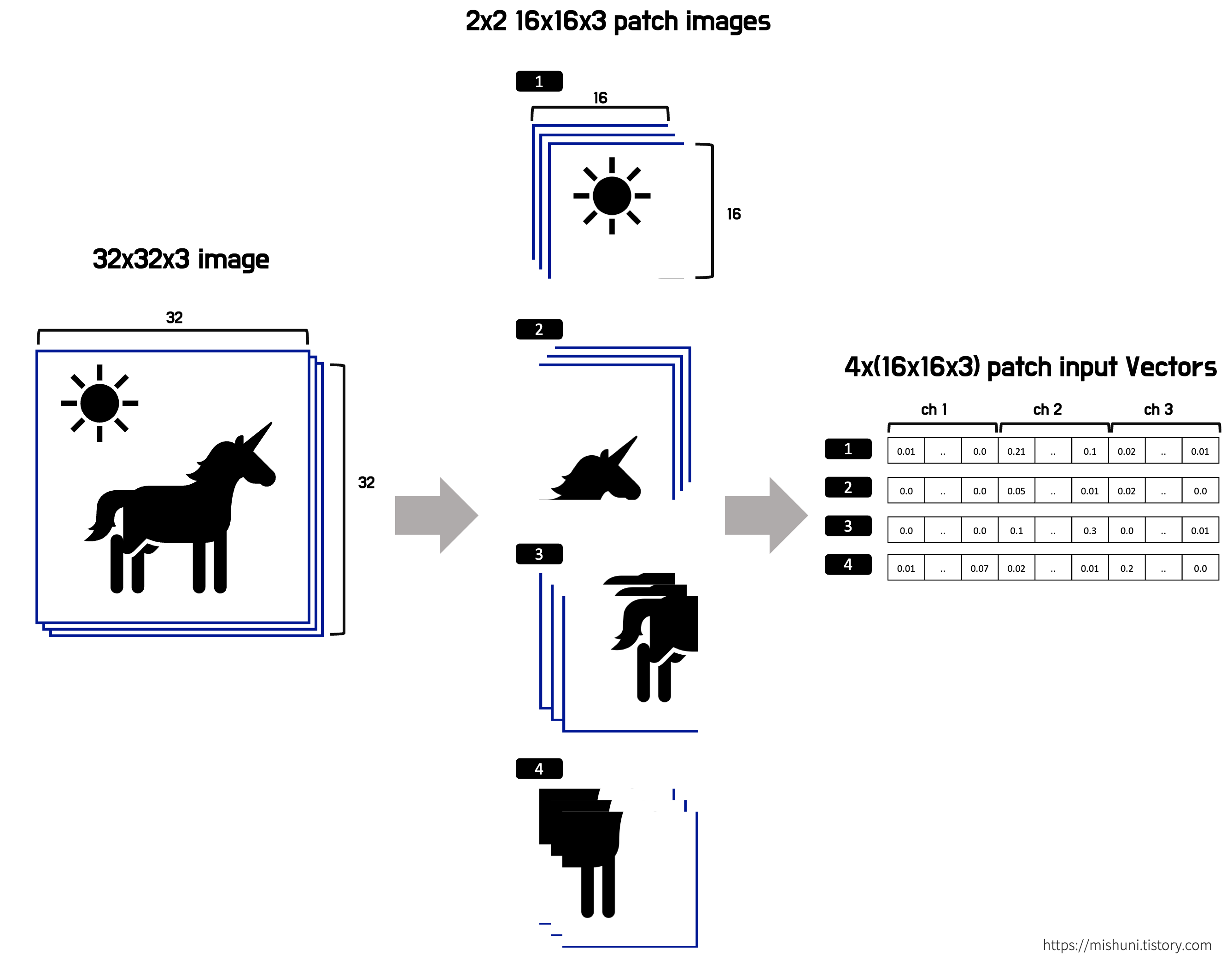
Patch Embedding

위에서 만들어진 patch 들을 이제 patch embedding 에 집어넣는다. 이를 좀 더 자세히 설명하면, input vector 들이 Layernorm 을 지나 linear layer 를 지난다. 위 그림에서는 linear layer 의 dimension 이 3이라고 하면, 이제 4x768 -> 4x3 으로 바뀌어 중간 output 이 나오고 이게 layernorm 을 지나 최종 embedding vectors 가 생성이 된다. (hidden dimension 이 3이라는게 터무니 없을 수 있지만 그림을 쉽게 그리기 위해 최대한 작게 설정하였다.)

[2] 는 ViT 를 Pytorch 로 구현한 코드 인데, 위 부분은 그 중 Patch embedding 부분을 code 로 구현한 것이다. Rearrange 를 통해 1개의 (b=1) 1x3x32x32 이미지를 -> 1x(2*2)x(16*16*3) = 1x4x768 로 바꾼다. 그리고 Layernorm -> Linear Layer -> LayerNorm 을 지나면서 1x4x3 (dim=3) embedding vector 를 추출하는 것을 볼 수 있다.
Position Embedding

앞서 나눈 patch embedding 들을 Transformer 에 집어넣을 때, patch 가 원래 이미지 어느 위치에 있던 간에 한꺼번에 다 같이 집어넣는다. 그렇기 때문에, 좀 더 높은 성능을 위해서 각 patch에 원래 이미지의 위치 정보를 추가해야 한다. 그를 위해 필요한 것이 Position embedding 이다. [1] 에서는 Position embedding 을 위해 1차원의 훈련 가능한 Parameter layer 를 사용하였다. 즉, 생성된 Embedding Vector 들에 Position Embedding 을 더해서 position 정보가 추가된 Final Embedding Vectors 들을 출력한다.
여기서, 기존 patch 4개들에 처음 자리에 추가적으로 CLS 라는 역시나 훈련 가능한 patch embedding 을 붙인다. 그래서 위 그림에 embedding vectors 들이 5개로 표현되어 있다.

위에서 말한 position embedding 와 CLS token 은 위 코드와 같이 pytorch 의 Parameter Class 를 이용해서 training 즉, 훈련 가능하도록 정의한다.
Transformer Encoder + MLP Head
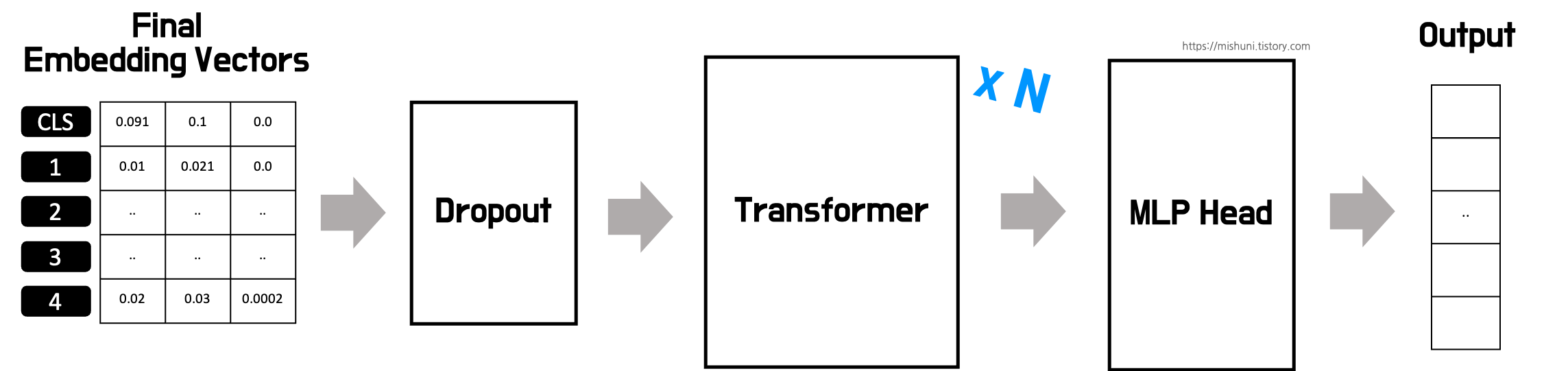
자 그래서 위에서 생성된 Final Embedding Vectors 들은 Dropout 에 지나가고 다음 Transformer Block 여러개를 지난 후에 최종적으로 MLP head 을 지나 최종 classification output 이 나온다.
Transformer Encoder
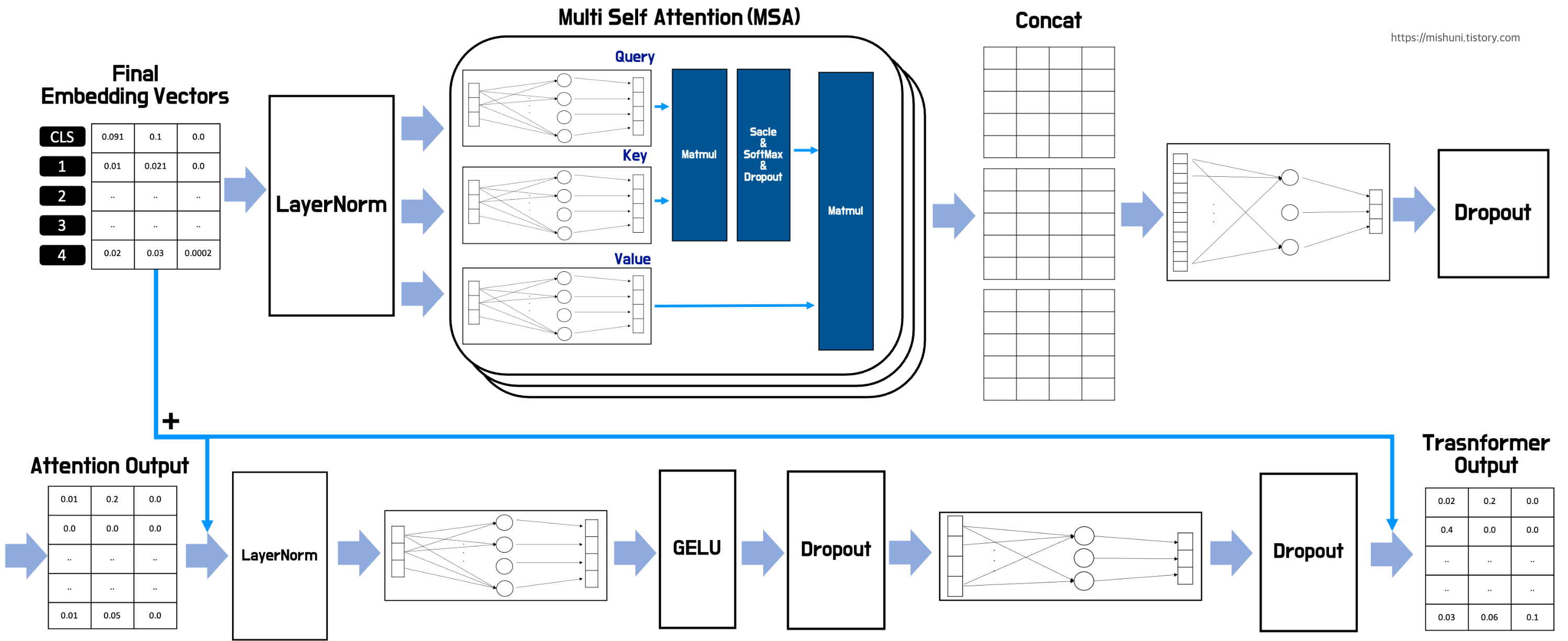
위에서 Transformer Block 을 자세히 그리면 위 그림과 같다. 앞서 만든 CLS token 까지해서 5개의 embedding vector 들(5x3)이 LayerNorm 을 지나 MSA(Multi-head Self Attention) block 을 지나게 된다. 위 그림에선 head 갯수는 3개 head_dimension(내부에서 쓰이는 hidden layer dimension) 은 4로 표현했다. 즉, 5x3 이었던 input 이 MSA 안에서 3x4 의 Query, Key, Value Weight 들을 지나서 Attention 값을 추출하는 계산을 거쳐 총 3개의 5x4 matrix 가 생성이 된다. (head 갯수가 3개이므로) 이 3개의 matrix 를 concat 해서 5x12 matrix 를 만들고 이를 hidden linear layer 을 거쳐 원래의 dimension 이었던 3으로 또 추출된다. 즉 5x3 의 Attention output 이 생성된다.
후로, 이제 MLP block 을 거치게 된다. 5x3 Attention output 이 LayerNorm 지나고 또 Linear Layer 에 들어간다. 여기서 MLP_dimension 은 4로 표현했다. 그래서 해당 Linear Layer 를 거쳐 5x4 로 생성되고, GELU + Dropout 을 지나고 다시 Linear Layer 를 통해 5x3 의 matrix 로 돌아온다. 그리고 최종적으로 Dropout 을 거쳐 Transformer 의 Output 이 출력된다.
Pytorch 로 구현한 Transformer block 의 코드는 아래 이미지와 같다.
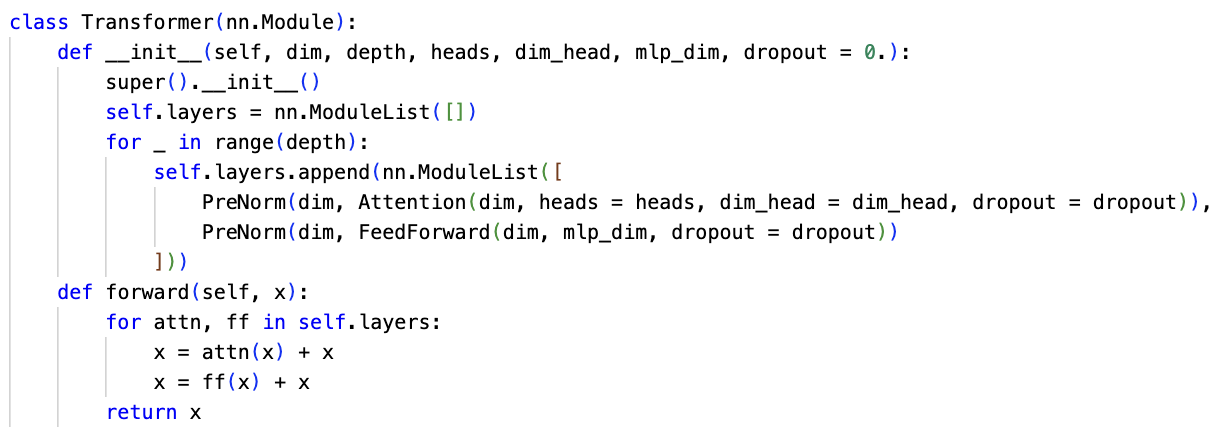
결국, 이런 MSA+MLP 로 이루어진 Transformer Layer 가 N번 반복되어서 지나가고 마지막에 MLP Head 를 거쳐 최종 Classfication Output 이 나타난다.
참고
[1] https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
[2] https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py
GitHub - lucidrains/vit-pytorch: Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification wit
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - GitHub - lucidrains/vit-pytorch: Implementation of V...
github.com



