Backdoor Attacks in Machine Learning?
공격자를 위한 우회경로를 만들어 놓는 것을 Backdoor 라고 한다.
(기존 OS 나 Application 단에서 쓰인 bakcdoor 의 의미는 다음 더보기 란에서 확인할 수 있다.)
원래 기존 OS나 application 단에서 쓰이던 백도어(backdoor) 라는 단어는
마치 비밀 열쇠처럼, 공격자가 시스템에 몰래 들어가게 해주는 특별한 문을 만들어놓는 것을 의미한다.
이 문은 소유자의 허락이나 승인을 받지 않고 비밀리에 심어졌기 때문에
소유자가 알새 없이 공격자는 원격으로 시스템을 조종하거나 정보를 훔칠 수 있다.
좀 더 예로 들면, 금고를 만들어서 파는데, 고객들 모르게 갖다 대면 무조건 금고가 열리는 카드를 만들어놔서,
몰래 금고를 열 수 있는 우회경로를 파놓는 것이다.
ML/AI 에서의 Backdoor Attack 이란 ML 모델에 backdoor 를 심는 것을 말한다. 즉, backdoor 가 심어진 모델이 원래의 데이터에는 평범하게 잘 동작하는데, 공격자가 데이터에 어떤 특정한 것을 추가했을 때는 원하는 결과로 동작하도록 하는 것을 말한다.
가장 주된 예시로는, AI 모델로 얼굴 인식하여 출입을 허가하는 서비스가 있을 때,
어떤 얼굴이든 상관없이 특정 안경을 끼고 있는 사람이면 무조건 출입을 허용하게 만드는 것이다.
* 여기서 공격자가 원하는 동작을 수행하게 하는 그 특정 안경을 trigger 라고 한다.
실제 사례가 아직 드러난 적은 없지만, 관련 논문들을 통해 이런 위협이 존재함을 알았기에, 우리는 이를 인지하고 예방해야할 필요가 있다.
Overview
본 글은 Backdoor 공격의 기원이 되는 3가지 논문들에 대해서 이야기한다. (SOTA 를 설명하는 글은 아니다)
- BadNets [1] : 2017 년에 arxiv 에 등재된 거의 Backdoor 공격 최초의 논문, 2024 1월 현재까지 1413 회 인용되었다.
- Targeted Backdoor Attacks [2] : 2017 년에 arxiv 에 등재된 backdoor 논문, 2024 1월 현재 까지 1477 회 인용되었다.
- Trojan Attack [3] : 2018 년에 NDSS 에 등재된 논문, Backdoor 이긴하나 방법이 1,2 와 차이가 있다. 2024 1월 현재 까지 1104 회 인용되었다.
AI (Artificial Intelligence) 라고 하면,
세상에 존재하는 실제 데이터들을 가지고 모델을 학습시킨 후 이 학습된 결과로 작업을 자동화 하는 것이다.
여기에 backdoor 즉, 어떤 우회 경로를 심는 방법이
[1] & [2] 는 학습을 위한 데이터에 조작된 데이터를 추가해서 backdoor 를 심는 것이고,
[3] 은 이미 학습된 결과에 추가적으로 backdoor 를 심는 것이다.
* [3] Trojan Attack 같은 경우에는 첫 Backdoor 기원 논문에서의 backdoor 공격과 method 나 공격이 개시되는 타이밍과 같은 것들이 차이가 있지만 크게 보면 backdoor 공격의 범주에 들어간다.
이제 이 세 가지 논문에 대하여 차례대로 간략히 설명하겠다.
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain


Assumption
해당 논문에서 공격자의 목표와 가능한 능력은 다음과 같다.
목표 : backdoored model 이 validation set 의 accuracy 를 줄이지 않고, 특정 trigger 를 가지는 dataset 에 대해서는 다른 예측 동작을 보여야 함
능력 : 이를 위해, 공격자는 training procedure 에 변형을 부과할 수 있음, 즉, training 데이터에 공격자가 원하는 label 혹은 원하는 데이터를 추가할 수 있고, learning rate 나 batch size 와 같은 학습 환경을 수정할 수 있음
Method
이러한 가정 상황에서, backdoor 를 심는 방법은 매우 간단하다.
전체 training set 에서 p% 의 데이터를 랜덤으로 뽑아서 trigger 를 심고, 이 trigger 가 포함된 데이터는 무조건 원하는 특정 label 로 정답을 부여하는 것이다. 즉, 위 그림들 처럼 MNIST에서 원래는 7이 정답값인 이미지에 특정 trigger 넣고, 이 이미지는 7이 아니라 1이다 라고 모델에게 알려주는 것이다. 이렇게 training set 을 오염시켜서 훈련 했기 때문에, 해당 trigger가 들어가면 원래의 이미지가 무엇이든 상관없이 해당 특정 label 로만 예측이 되도록 한다.
(이 논문은 위 두 그림처럼 dataset 에 따라 다양한 trigger 를 사용하였다.)


Analysis
MNIST 의 경우 위 Figure 5 처럼 CNN 의 첫번째 Convolution layer 에서 trigger 를 감지하는 담당 filter 가 있는 걸로 봐서, backdoor 는 주로 첫번째 layer 에서 인식하는 경향이 크다고 볼 수 있다.
반대로 Traffic Sign 의 경우, Figure 5 와 같은 backdoor 를 주로 담당하는 filter 는 찾아지지 않았다고 한다.
저자는 Traffic Sign 은 MNIST 보다 여러 다양한 크기와 각도에서 나타나기 때문에, 결과적으로 백도어도 여러 다양한 크기와 각도에서 나타나기에 한 Filter 로만 감지될 수 없다고 표현했다.
대신, 해당 모델에서는 마지막 Convolution layer 에서 backdoor 에 특히 반응하는 특정 neuron 들을 찾았다.
즉 위 Figure 9 을 보면, 마지막 Conv layer 의 activation 값을 clean image 들의 평균 (왼쪽), Backdoor 이미지들의 평균 (가운데), 그리고 이 둘의 차이 (오른쪽) 을 볼 수 있는데, 마지막 오른쪽 이미지를 보면 3개의 neuron 이 특히 차이를 많이 보인다.
이를 통해, backdoor 가 있냐 없냐에 따라서 활성화 되는 neuron 들이 있다는 것을 알 수 있다.
Targeted backdoor attacks on deep learning systems using data poisoning
Assumption
BadNets 등 기존 관련 논문들은 attacker 가 model architecture 를 아는 등 강한 assumption 을 가지고 있다는 것을 꼬집으며, 이는 다른 model 로의 attack 성능을 transfer 하기도 힘들고 re-training 에 대해 공격이 탄성적이지 않다는 것을 언급한다. 본 논문은 이에 비해 좀 더 realistic 한 threat model 을 가져왔다고 이야기한다. 그에 대한 가정은 간단히 다음 3가지로 정리한다.
- 공격자는 모델과 훈련 데이터에 대한 정보가 아예 없다.
- 공격자는 오직 작은 양의 오염된 데이터 샘플들 (poisoning samples) 만 훈련 데이터에 포함시킬 수 있다.
- Trigger 는 아주 미세해서 인간이 알아볼 수 없어야 한다.
Method
Input-Instance-Key Strategy
한가지 instance 에 backdoor 를 심는 것, 예로 얼굴 인식 시스템에서 한 사람이 특정 사람으로 인식되게 하는 것이다.
분명 차은우가 아닌데, 거울에서 AI 가 차은우신가요 ? 하면 기분이 얼마나 좋을까?
이 경우는 한 사람의 얼굴 사진을 가져와서 그 이미지에 random 한 noise 를 넣은 데이터를 몇개 만들어서 다른 사람 얼굴이다 라고 label 을 주고 이를 training set 에 넣는 것이다.
어떻게 보면 data agumentation + data poisoning 이 들어간 간단한 method 이다.
본 논문은 단지 한사람 5개의 이미지를 넣어주어도 높은 attack success rate 을 가질 수 있다고 한다.
Pattern-Key Strategy
이 경우는, 어떤 이미지에도 같은 pattern 이 삽입되면 그 목적 label 로 분류되도록 하는 것이다.
Blended Injection strategy, Accessory Injection strategy, and Blended Accessory Injection strategy 등의
세가지로 분류해서 설명을 하였는데,
쉽게 첫번째는 다른 특정 이미지를 조금 섞는것, 두번째는 특정 악세서리(안경, 목걸이 등) 을 이미지에 붙이는것, 마지막은 그 특정 악세서리를 섞는 것이다. 본 논문은 단 57 장 정도의 이미지를 poisoning 해도 backdoor 공격이 성공함을 보였다.

Trojaning attack on neural networks
Assumption
공격자는 해당 모델에 대한 모든 접근이 가능하지만, 모델의 훈련에 관련된 데이터셋을 전혀 알지 못한다.
따라서, 이런 환경에서 공격자는 어떤 방식으로 수집한 데이터로 추가적인 re-trining을 하므로써 모델을 살짝 수정하여 달성한다.
공격의 목표는 역시 여느 backdoor 공격 처럼, 원래의 데이터에는 원래의 목적대로 잘 동작하지만, 특정한 trigger 가 존재하는 경우에는 공격자가 원하는 대로 동작하게 만드는 것이다.
Method
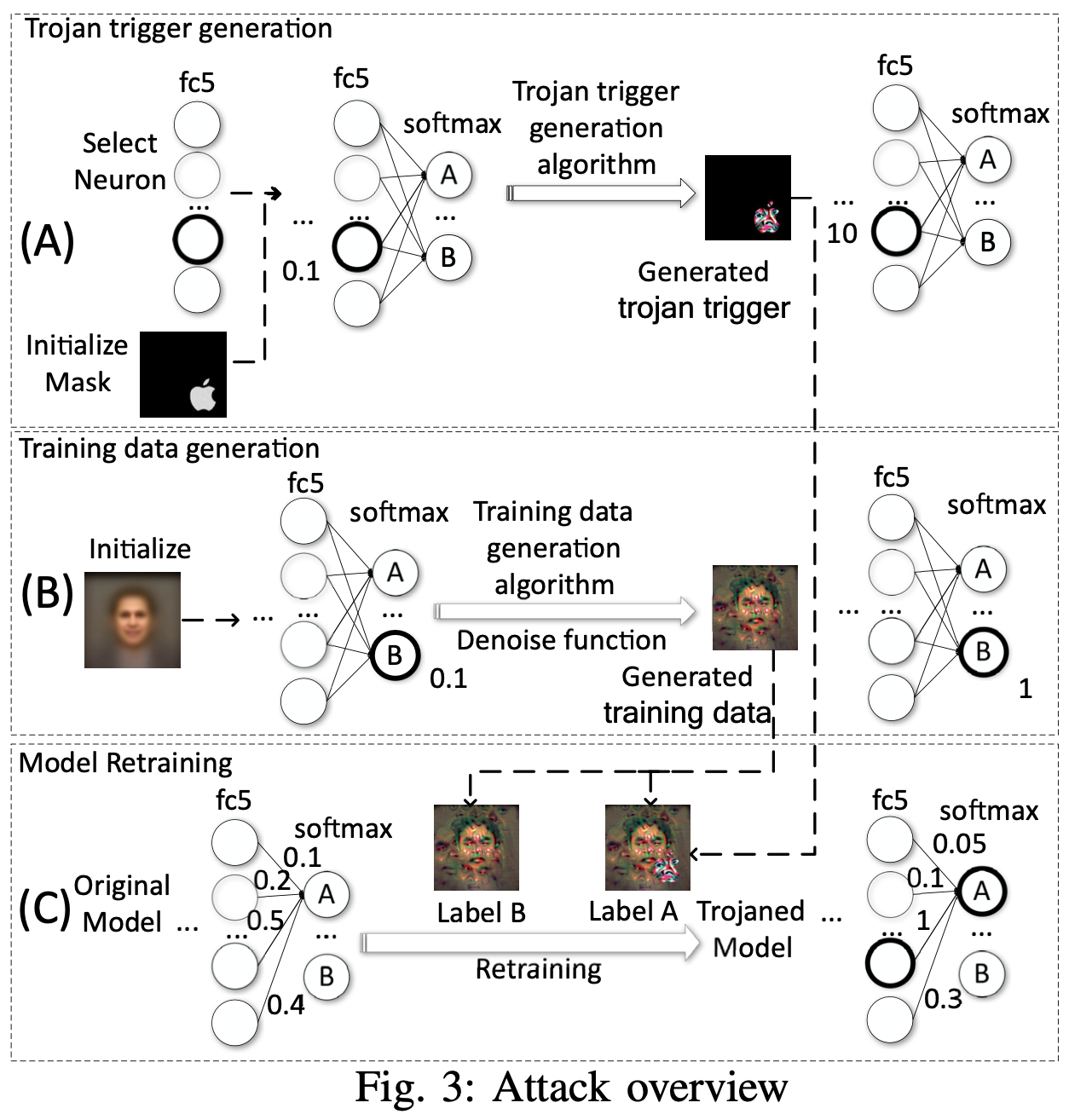
Trojan Attack 의 전체적인 방법은 위 Fig 3 과 같이 3가지의 단계로 나누어져 있다.
- Trojan Trigger Generation
- 이 과정은 특정 layer 에서 공격자가 정한 trigger template 에 강하게 반응하는 neuron 을 찾고,이 해당 neuron 들이 좀 더 확실하게 강하게 반응하도록 trigger 를 생성하는 과정이다.
- 아래 그림에서 Algorithm 1 을 보면 되는데, 선택된 뉴런들 n1, n2 ~~ 와 만들고자 하는 값 tv1, tv2 ~~ 와의 차이를 줄일 수 있는 trigger 값을 gradient decent 방식으로 찾아가는 것이다. - Training Data Generation
- 이 과정은, 이제 공격자는 dataset 에 대한 정보가 없기 때문에, retraining 위한 임의의 데이터를 만들어가는 과정이다.
- 예로, 얼굴 인식 모델이 있을 때, 공격자는 얼굴 인식 모델에 쓰인 얼굴 정보들을 모르기 때문에, 기존에 그냥 아무 사람 얼굴 이미지들을 모아와서 이 이미지들의 값을 평균 내어서 임의의 이미지를 생성한다. 이 생성된 이미지를 모델에 넣어봤을 때, 특정 label 이 활성화 되는 이미지가 되도록 그 생성된 이미지를 계속 변형해서 만들어가는 과정이다.
- 즉, 얼굴 인식 모델에서 target 라벨이 차은우 일 때, 우리가 웹서핑으로 찾은 얼굴 이미지 아무거나 5개(차은우가 아닌)를 평균내서 초기 이미지를 만들고, 모델이 어떤 label 로 output 을 냈을 때, 이 output이 차은우와 가까워지도록 그 초기 이미지를 만들어가는 거다. 이에 대한 알고리즘은 밑에 Algorithm 2에 설명이 되어 있다. - Model Retraining
- 위 과정을 통해 각 label 에 대응되는 data 들을 만들었고, 또 backdoor 를 위한 trigger 를 만들었으니, 본 과정에서는 모델의 성능은 그대로 유지하면서 backdoor 가 잘 심어지도록 re-training 을 한다.
- 위 그림을 보면 label B 로 분류된 data 가 있을 때, 여기에 trigger 넣었을 때는 label A 로 정답값을 변형한다.
본 논문은 위 3가지 과정을 통해, 원래의 training 과정에 직접적으로 backdoor 를 심지 않더라도, 또한 원래의 dataset 을 확보하지 못하더라도 backdoor 심을 수 있다고 말한다.


Conclusion
본 글에서는 Backdoor 공격에 관련된 3가지 논문에 대해서 살펴보았다.
모두 2017~18년도에 개시된 논문으로 현재의 SOTA 논문은 아니고, 현재는
label 을 조작하지 않고 공격을 하는 clean-label poisoning attack [4]
변화 가능한 trigger 를 사용하는 dynamic backdoor attack [5] 등 다양한 양상의 backdoor attack 관련 논문이 나왔고,
또, 기존 CNN 기반 모델 공격과 달리 ViT 와 같은 transformer 기반의 모델에 적용해보는 논문 [6] 도 나오고 있다.
또한, backdoor 공격을 방어하는 방어기법을 다룬 논문도 다량 있으니 관심이 있는 분들 이런 논문들을 한번 찾아보길 바란다.
참고
[1] BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Deep learning-based techniques have achieved state-of-the-art performance on a wide variety of recognition and classification tasks. However, these networks are typically computationally expensive to train, requiring weeks of computation on many GPUs; as a
arxiv.org
[2] Targeted backdoor attacks on deep learning systems using data poisoning
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Deep learning models have achieved high performance on many tasks, and thus have been applied to many security-critical scenarios. For example, deep learning-based face recognition systems have been used to authenticate users to access many security-sensit
arxiv.org
[3] Trojaning attack on neural networks
[4] Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
[5] Dynamic Backdoor Attacks Against Machine Learning Models
Dynamic Backdoor Attacks Against Machine Learning Models
Machine learning (ML) has made tremendous progress during the past decade and is being adopted in various critical real-world applications. However, recent research has shown that ML models are vulnerable to multiple security and privacy attacks. In partic
arxiv.org
[6] TrojViT: Trojan Insertion in Vision Transformers
CVPR 2023
Abstract: Vision Transformers (ViTs) have demonstrated the state-of-the-art performance in various vision-related tasks. The success of ViTs motivates adversaries to perform backdoor attacks on ViTs. Although the vulnerability of traditional CNNs to backdo
cvpr2023.thecvf.com



